Trusted by market leaders in Uzbekistan











GPUaaS powered by NVIDIA DGX B200 — the most powerful next-generation AI platform. Train LLMs, run inference, and solve HPC tasks in Uzbekistan's sovereign cloud.
Trusted by market leaders in Uzbekistan
Fine-tuning corporate models, SFT, LoRA/QLoRA, and distributed training across multiple GPUs.
Running LLMs and multimodal models, corporate AI services, agents, and low-latency inference.
CV, OCR, speech, video analytics, processing large datasets, and accelerated inference.
Numerical modeling, CUDA applications, parallel computing, and resource-intensive research tasks.
Training and fine-tuning models, LLM experiments, scaling tasks from 1 GPU to multi-GPU and multi-node configurations.
Data, models, and pipelines remain within Uzbekistan's local circuit — without exporting sensitive information to external clouds.
For resource-intensive computing, research, production inference, and launching AI services with predictable performance.

The generation succeeding Hopper (H100/H200). A more advanced platform for training, fine-tuning, and inference of enterprise-grade AI models.

Allocate resources for specific tasks: from individual GPUs to multi-GPU and multi-node configurations for distributed training and production workloads.
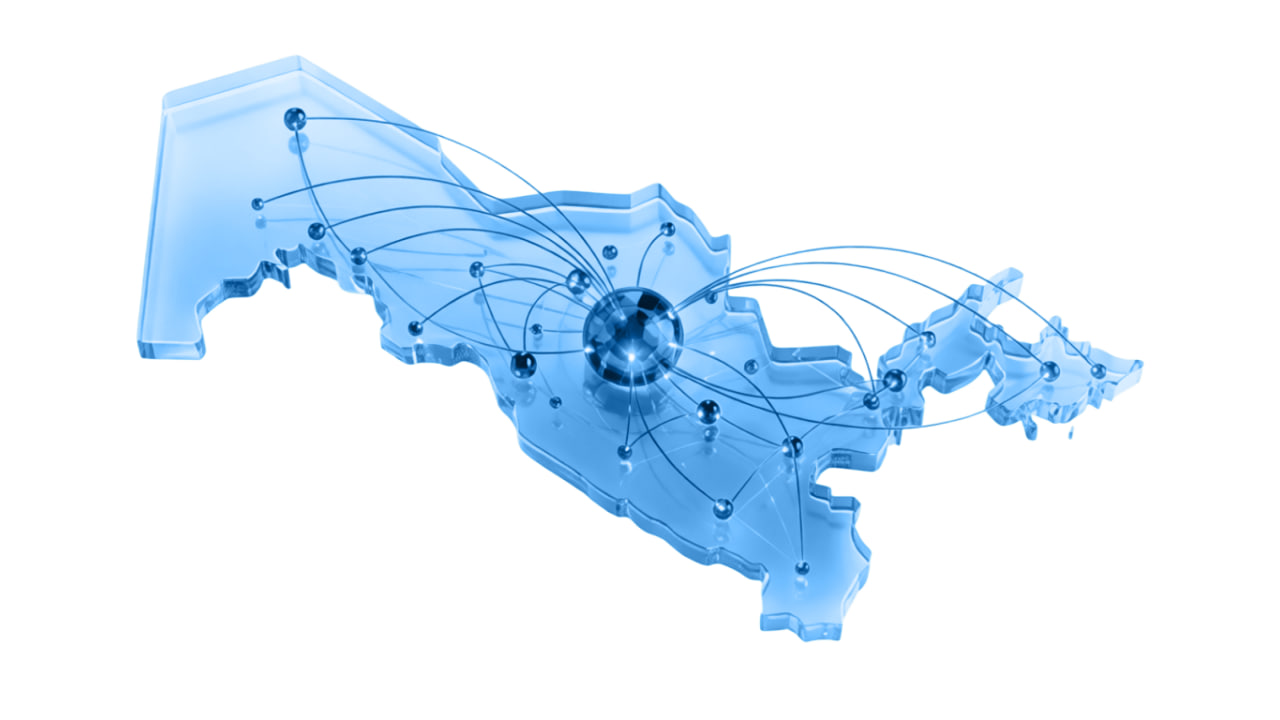
Infrastructure is hosted locally: lower latency, faster data processing, and compliance with sensitive information storage requirements.

Support for CUDA ecosystem, NVIDIA NGC, PyTorch, TensorFlow, Docker containers, and popular MLOps scenarios without lengthy manual setup.
Datasets, model weights, and compute results remain within the local circuit — crucial for enterprise, fintech, and regulated industries.

Fast data exchange between GPUs within a node and between cluster nodes helps run distributed training and heavy inference more efficiently.
Computing resources based on NVIDIA Blackwell B200 on the DGX platform are available. Configurations are tailored to the task: from a single GPU to multi-GPU and cluster scenarios.
B200 is built on the Blackwell architecture — the next generation after Hopper (which H100 and H200 are based on). For AI and LLM workloads, it is a more advanced platform with more GPU memory and better readiness for large-scale GenAI scenarios.
Access is provided via API endpoints based on the Run:ai platform. You receive an endpoint to deploy containers and manage workloads without manual server configuration.
Yes. We support configurations from 1 GPU to multi-GPU and multi-node scenarios for distributed training, inference, and HPC tasks. Scaling is managed via Run:ai — without requiring our team's involvement for every request.
The infrastructure is located in Uzbekistan. This ensures a local data storage circuit and minimal access latency for users within the country.
The infrastructure runs on Run:ai — you receive an endpoint and deploy containers yourself. Standard PyTorch, TensorFlow, vLLM images, and custom Docker containers are supported. If needed, our team assists with onboarding and the initial launch.
Get a free consultation with a solutions architect. We'll help plan your migration and optimize costs.